
We will take the below XML file as example for our exercise so please take a moment to understand the data and format Sample XML CD Catalog Fig 1.

This is how the data looks in the browser. InfoCaptor allows for complete XPATH selectors and querying of XML documents. It is extremely powerful if you know how to leverage XPATH. At the bottom of this document there are references to XPATH tutorials in general. Connection : HTTP Output as XML – Any URL that is public

Parameters
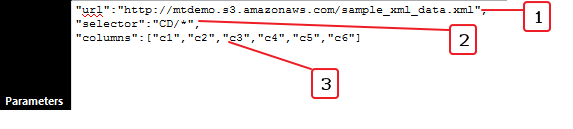
1. “url”:”http://mtdemo.s3.amazonaws.com/sample_xml_data.xml”,URL is the source for the XML document. The above URL contains the data as shown in the figure 1.
2. “selector”:”CD/*”, This is the Xpath selector. In the above example we want all the child elements of the “CD” node (tag).
3. “columns”:[“c1″,”c2″,”c3″,”c4″,”c5″,”c6”]
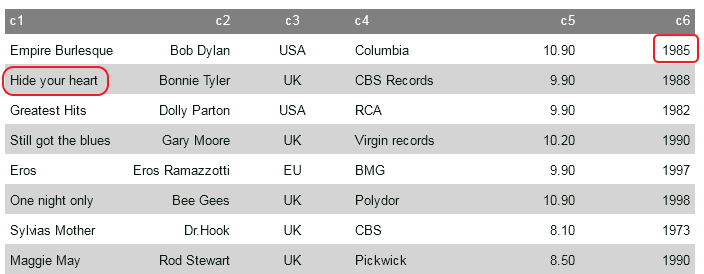
Under the “CD” node we can see that there are 6 different child elements. When InfoCaptor parses the XML document it returns all child elements in one stream. It does not come in rows and columns.
It is just a continuous stream of child elements that match the selector. So when you mention the column names in the “columns” parameter it splits the stream in to chunks of rows and the number of elements in each row is determined by the number of columns defined in the above “columns” array. So if we define 6 columns (any names you desire) we get this in a grid visual Fig 2
Now if we change the number of columns to 5 we get this Fig 3

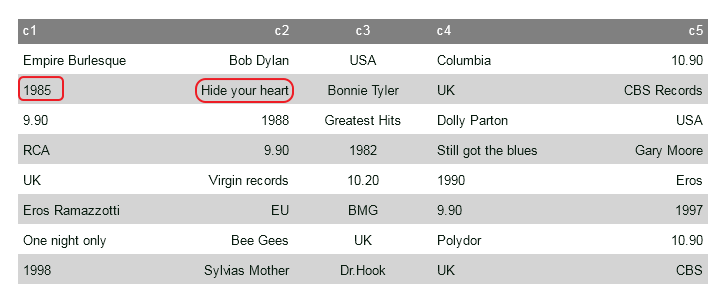
Since we reduced the number of columns in a row, notice how the “1985” cell got pushed to the second row in Fig 3. Similarly all the cells get pushed one position away. So, What happens if you just provided one column?

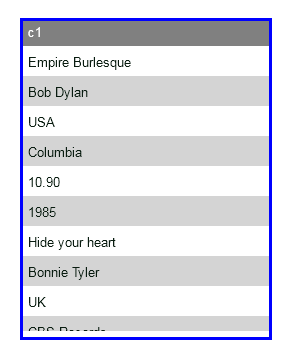
So this gives a very powerful way of streaming your XML data. Please refer this quick article to get familiar with XPATH syntax Let us try some more examples Problem Statement : Show all the titles from the XML document
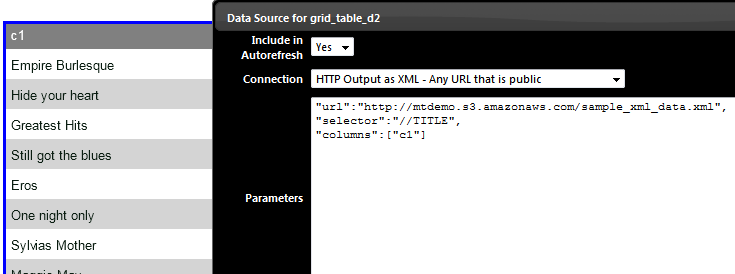
we use the “//TITLE” as the selector. With the “//” we can go directly to any depth of the XML document and fetch all the elements that match the node name. Similarly we can individually pick the list of Artists etc
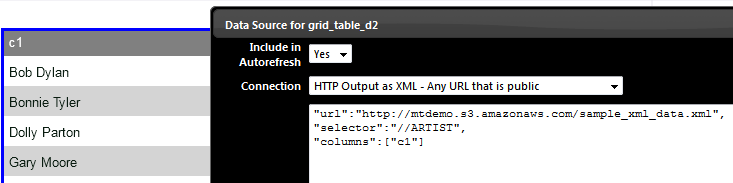
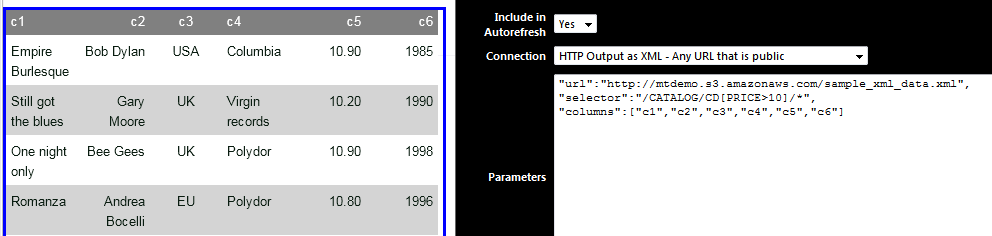
Problem Statement : Show all the CD records with price greater than 10 “url”:”http://mtdemo.s3.amazonaws.com/sample_xml_data.xml”,”selector”:”/CATALOG/CD[PRICE>10]/*”,”columns”:[“c1″,”c2″,”c3″,”c4″,”c5″,”c6”]
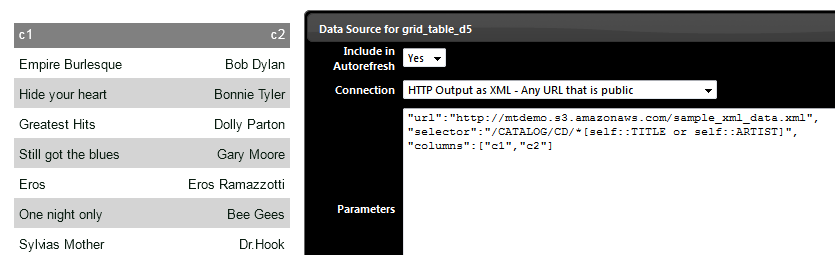
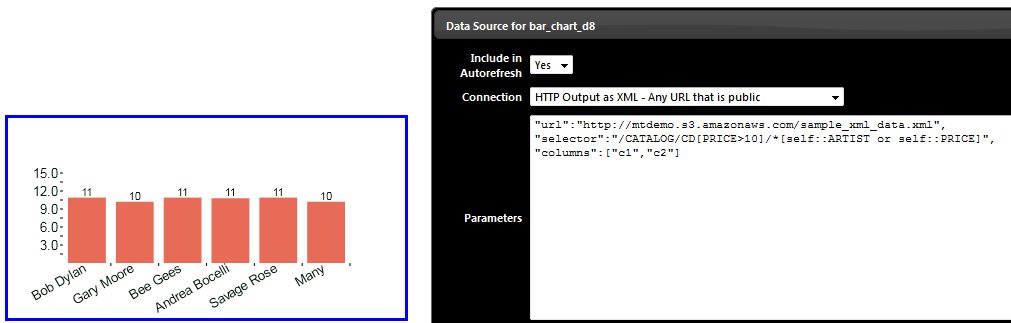
Problem Statement : Show a list of all the Titles and Artist only (don’t show other columns) “url”:”http://mtdemo.s3.amazonaws.com/sample_xml_data.xml”,”selector”:”/CATALOG/CD/*[self::TITLE or self::ARTIST]”,”columns”:[“c1″,”c2”]
You can plot the data on a bar chart as well
References http://www.w3schools.com/xpath/xpath_intro.asphttp://www.w3schools.com/xpath/xpath_nodes.asphttp://www.w3schools.com/xpath/xpath_syntax.asphttp://www.w3schools.com/xpath/xpath_axes.asphttp://www.w3schools.com/xpath/xpath_operators.asphttp://www.w3schools.com/xpath/xpath_examples.asp