
Extracting information from a HTML page is similar to the techniques mentioned in the XML section We use the same XPATH selector to extract html tags such as DIV, TD etc Example:
We have a local copy of a similar pricing table and we want to simply scrape and show it on our dashboard
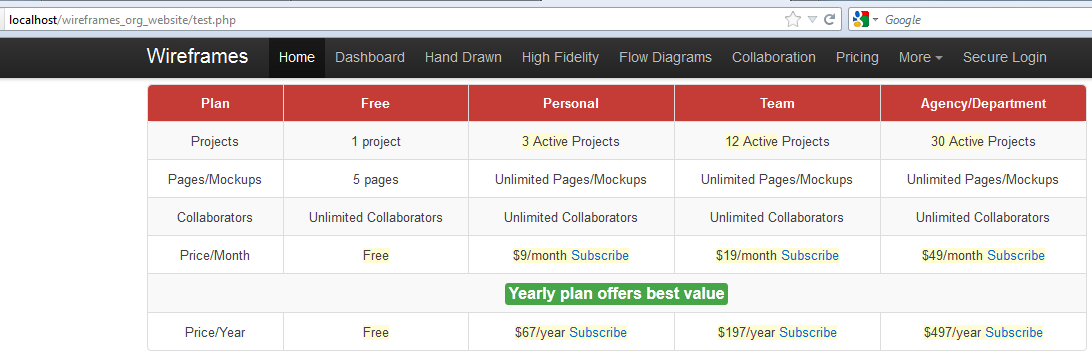

“url”:”http://localhost/wireframes_org_website/test.php”,”selector”:”//*[@id=’pricing_home_table’]/tbody/tr/*”,”columns”:[“c1″,”c2″,”c2″,”c2″,”c2”] The ID for the table is “pricing_home_table” and you can use firebug to even get the XPATH of any tag in the HTML page. This works exactly like the XML Output so please refer the examples