
InfoCaptor now officially works and certified with Cloudera’s Hadoop distribution and specifically with Hive and Impala.

Earlier InfoCaptor supported only JDBC protocol but now along with CDH integration, it has introduced ODBC protocol to take advantage of efficient drivers from Cloudera (Cloudera – Simba drivers) and provide more platform connectivity options.
The integration has been exhaustively tested against amazon EC2 clusters with CDH 5.1 and CDH 5.4 versions.
It has also been tested with standalone Cloudera Sandbox VM
Once you get connected to either Impala or Hive you can perform drag and drop visualization just like with any other data source.
InfoCaptor adds native Impala and Hive functionality within the Visualizer so you can leverage Date/time functions for date hierarchy visualizations.
Our latest InfoCaptor build for windows is a self contained package that you can download and use it against Hadoop. It can be downloaded here http://infocaptor.s3.amazonaws.com/infocaptor_enterprise_setup.exe
Once you download InfoCaptor, you will need appropriate drivers from Cloudera and establish the connectivity as documented in “How to connect Infocaptor to Cloudera Hadoop“.
Here is a sample analysis performed within Visualizer against Impala.
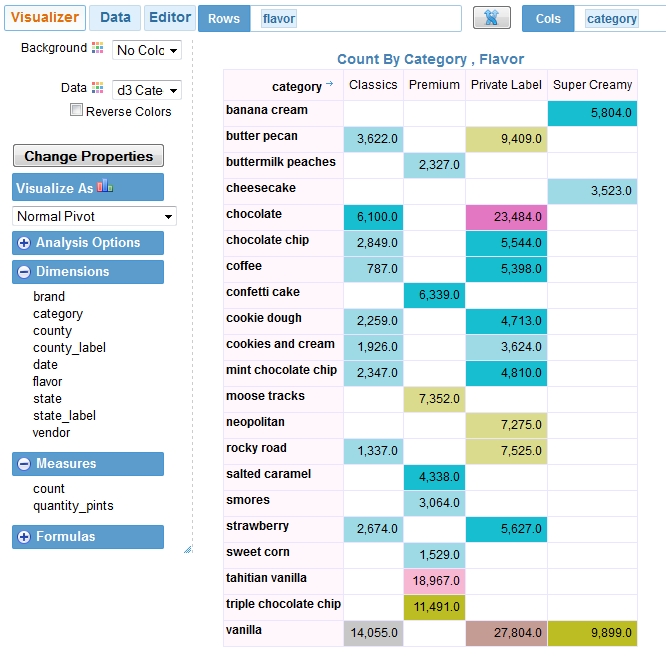
Analyzing Big Data on Cloudera Hadoop is just a drag and drop operation!